

飞牛NAS装个中文TTS服务
让NAS开口说话
NAS · Docker · 中文语音合成
先说结论: AngeVoice 是一个把中文 TTS 封装成 Docker 服务的开源项目。装到飞牛NAS 上之后,你的 NAS 就变成了一个本地文字转语音后端,AI 助手、阅读器、智能音箱、自动化脚本都能通过 API 调它。一条 docker compose up -d 就能跑起来。
NAS 除了存文件、挂下载、跑 Docker,还能干什么?
最近飞牛OS 社区有人分享了一个很有意思的项目——AngeVoice。它不是那种重训练的新模型,而是把 Kokoro 中文 TTS 和可选的 MOSS-TTS-Nano 封装成一个适合 NAS / Docker 长期运行的语音合成服务。
简单说,就是把你的 NAS 变成一个本地文字转语音服务,24 小时在线,内网其他设备都能用。
· · ·
AngeVoice 是一个开源的中文 TTS 服务项目,GitHub 上可以找到。它最大的特点不是"训练了一个新模型",而是"把现有的中文 TTS 模型包装成了一个适合长期运行的服务"。
它内置了 Kokoro 中文 TTS 和可选的 MOSS-TTS-Nano,提供了 Web UI、OpenAI 兼容 API、WebSocket 流式输出,还支持批量合成、健康检查、请求统计、缓存、限流等服务化功能。
它不是单纯的模型推理脚本,而是一个可以长期跑在 NAS 上的 TTS 后端服务。
· · ·
部署好之后,内网其他应用都可以通过 API 调用这个 TTS 服务。实际能用的场景比想象中多:
AI Agent 语音回复: 上一篇讲的 Hermes Agent 接上 TTS,AI 回应用语音读出来,体验瞬间不一样。
小智 ESP32 / 智能音箱后端: 很多 DIY 智能音箱项目需要本地 TTS 服务,AngeVoice 正好补上这一块。
阅读器朗读: 配合 NAS 上的电子书管理工具,文字转语音播报。
有声书生成: 把文章、文档批量合成语音,生成自己的有声内容。
视频配音草稿: 做视频的时候脚本转语音,先听一遍节奏再录音。
家庭通知提醒: NAS 监控到异常(比如硬盘温度过高),直接语音播报到家里音箱。
自动化脚本语音播报: 定时任务执行完,用语音告诉你结果。
· · ·
部署方式和之前的 Hermes Agent 类似,全程在飞牛OS 的 Docker 管理界面操作,不需要敲命令行。
启动之后,打开 http://你的NAS地址:8100,就能看到 AngeVoice 的 Web 界面,直接在浏览器里输入文字就能生成语音。
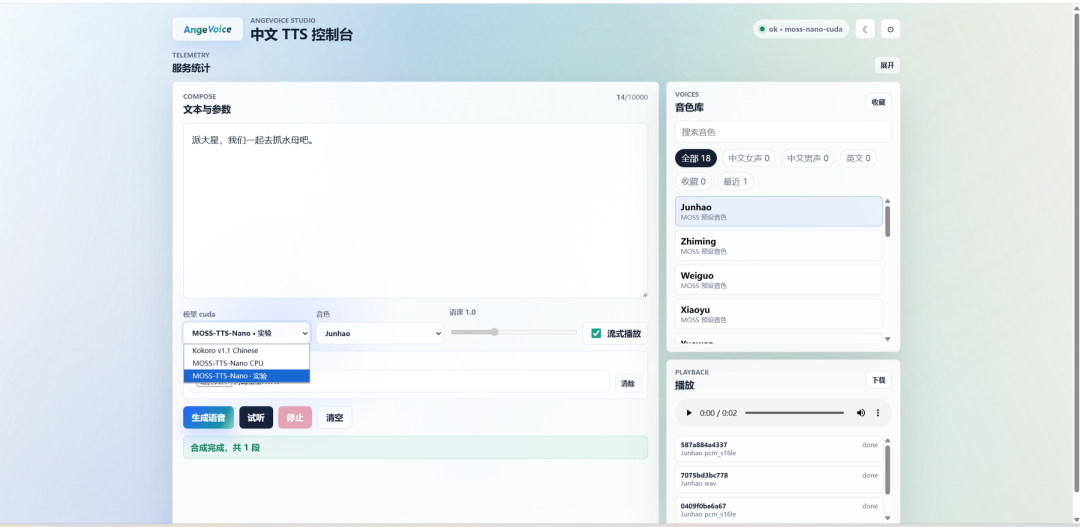
· · ·
CPU 模式(Kokoro): 普通 CPU 就能跑,建议 8GB 内存以上,16GB 更舒服。社区有人用 i3-9100T + 16GB 内存跑,Kokoro 流式生成速度还不错。
GPU 模式(MOSS / 参考音频克隆): 最好有 NVIDIA 显卡,CPU 上体验会比较慢。
需要说明的是,这类轻量 TTS 模型本身参数规模有限,音质和自然度不能和大型商业 TTS 服务硬比。它更适合本地化、自托管、低成本的使用场景,追求的是"能用且可控"而不是"媲美真人"。
· · ·
OpenAI 兼容接口: 它支持 /v1/audio/speech 接口,这意味着任何支持 OpenAI TTS API 的客户端都可以直接连过来用,不需要额外适配。
WebSocket 流式输出: 支持流式语音合成,文字一边生成一边输出音频,延迟比等全部合成完再返回低很多。
批量合成: 可以一次性提交多段文字,打包成 ZIP 下载,适合有声书、文章批量转语音的场景。
服务化功能: 健康检查、请求统计、缓存、限流都有,适合长期稳定运行。
· · ·
总结一下: AngeVoice 把 NAS 从一个"只存数据"的设备变成了一个"能产出内容"的服务。中文 TTS、Docker 部署、OpenAI 兼容 API,三个特点加在一起,让它在飞牛NAS 上有了不少想象空间。
项目地址:github.com/ang77712829/AngeVoice,MIT 协议,开源免费。如果你也在折腾 NAS,不妨试试。
— E N D —
科技智趣坊
分享科技好物,让生活更有趣